
[CSAPP] BOMB LAB 풀이
CS:APP LAB 자료 링크: http://csapp.cs.cmu.edu/3e/labs.html
혹시 잘못된 내용이 있다면 메일이나 댓글로 알려주시면 정말 감사하겠습니다
Tips
- 문제를 풀기 전에,
CS:APP교재의 3장을 끝까지 보고 푸시기 바랍니다. 저자의 강의(https://scs.hosted.panopto.com/Panopto/Pages/Sessions/List.aspx#folderID=%22b96d90ae-9871-4fae-91e2-b1627b43e25e%22)에서 3장 중간에Bomb lab이 소개되길래 거기까지만 공부하고 문제를 풀었는데, 알고보니 뒤의 내용을 알아야 코드를 이해할 수 있는 부분이 많았습니다. - 관심이 가는 instruction에 gdb의 break point를 걸고
x/[length][format] [Address Expression]명령어를 활용해 레지스터와 메모리의 값들의 변화를 관찰하는게 이 어셈블리 코드가 직관적으로 무엇을 하는 코드인지 이해하는 데 많은 도움이 되었습니다.
phase1
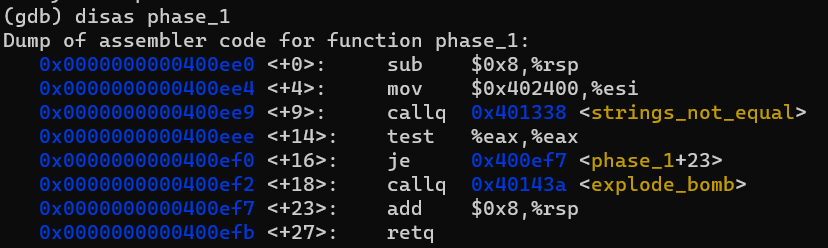
어셈블리 코드를 관찰해보겠습니다. strings_not_equal 함수를 호출해서 나온 결과값은 %rax(의 하위 32bit인 %eax)에 들어있을 것입니다.
test명령어로 %eax & %eax 연산을 수행했을 때 0이 나오면 jump 명령어로 인해 폭탄은 터지지 않고 정상적으로 해제되고, 0이 아닌 다른 값이 나오면 폭탄이 터집니다.
자기자신과 &연산을 한 결과가 0인 경우는 %eax 값이 0인 경우뿐입니다.
함수명과 어셈블리코드에서 유추할 수 있듯 strings_not_equal 함수는 입력받은 문자열이 %esi에 들어있는 문자열과 일치하지 않으면 1을, 일치하면 0을 반환하는 함수입니다.
그러면 우리가 해야할 일은 0x402400에 들어있는 문자열을 알아낸 후 똑같은 문자열을 입력해줘서 jump를 발생시키는 것입니다. 이를 위해 x/s 명령어를 사용합니다.

Answer
Border relations with Canada have never been better.
phase2
read_six_numbers 함수를 먼저 찾아보겠습니다. disas 명령어를 사용한 결과는 다음과 같습니다.
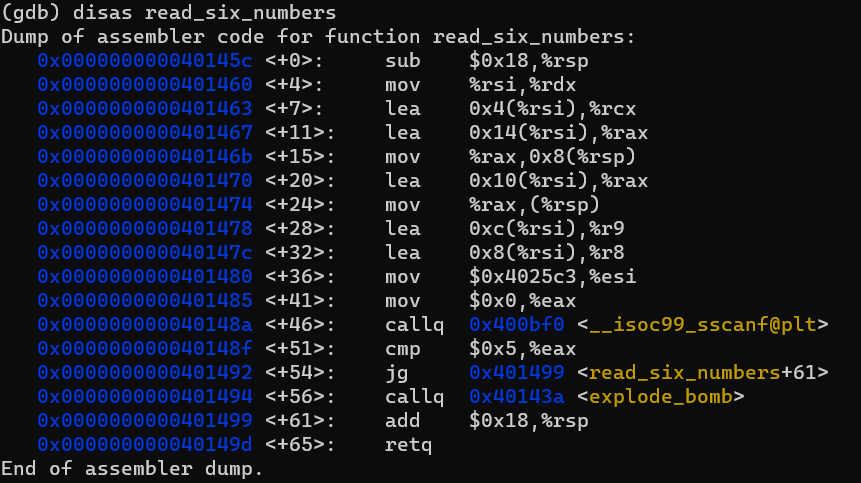
<+36>에 있는 $0x4025c3에 뭐가 들어있는지 확인해봅니다.

즉, 우리는 공백 하나를 사이에 두고 6개의 십진수 숫자를 입력해야함을 알 수 있습니다.
이제 phase_2의 코드를 관찰해보겠습니다.
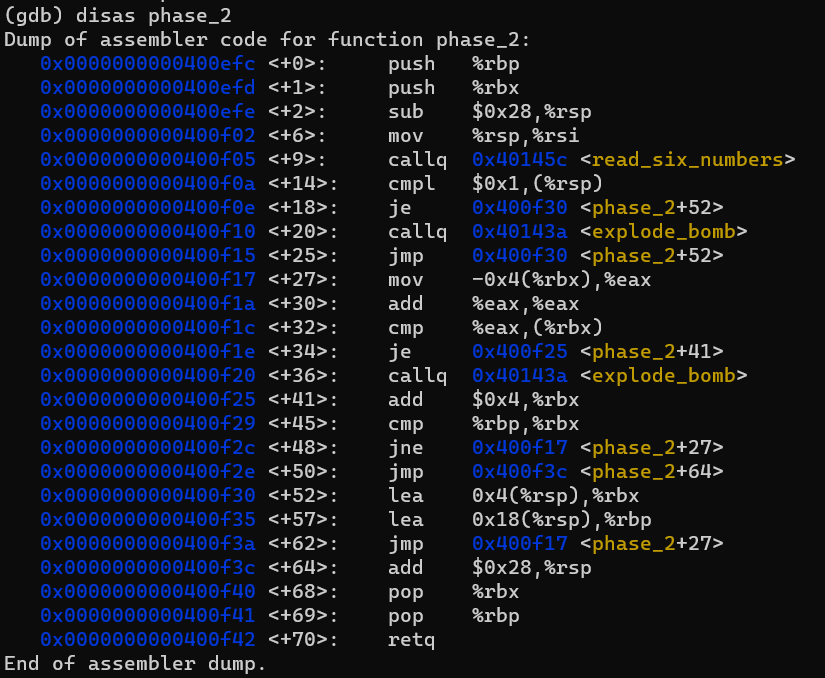
먼저 <+14>를 보면 stack top의 값이 0x1이 아니면 폭탄이 터진다는 사실을 알 수 있습니다.
그러므로 우리가 처음으로 입력해야 할 수는 1입니다.
%rbx는 스택에서 우리가 숫자를 확인할 index라고 볼 수 있습니다.
그리고 <+27>, <+30>, <+32>를 관찰해보면 (스택의 현재 index에 있는 값) * 2 == 스택의 다음 index에 있는 값 임을 알 수 있습니다.
<+62>는 반복문에서 벗어날 조건문의 역할을 합니다.
종합해보면, 처음 입력되어야 하는 수는 1이었고 그 뒤로는 계속 2배를 해주면 되는 것입니다.
Answer
1 2 4 8 16 32
phase3
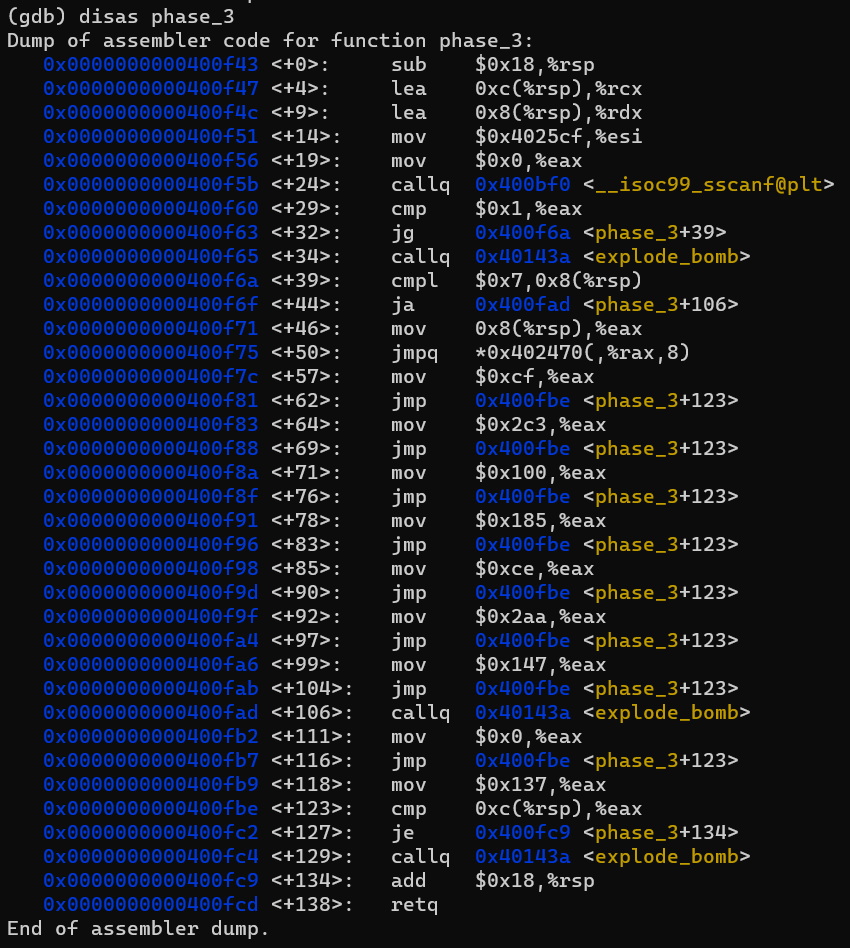
먼저, 입력 형식을 알기 위해 phase2에서 했던 것처럼 x/s 명령어를 사용합니다.

공백 하나를 사이에 두고 십진수 두 개를 입력해야함을 알 수 있습니다.
<+39> 을 보면, 첫번째로 입력한 인자는 0 이상, 7 이하입니다. (ja 명령어는 unsigned 형식으로 대소를 비교하기 때문입니다.)
<+50> 을 보면 이 코드는 jump table이 있는 switch-case 문임을 알 수 있습니다. jump table의 내용을 보기 위해 다음과 같은 명령어를 입력합니다.

x/[length][format] [Address Expression] 형태의 명령어를 사용해 jump table의 요소들을 찾아낸 것입니다. (syntax 참고: https://visualgdb.com/gdbreference/commands/x)
첫번째 인자는 0~7 사이 정수를 아무거나 정하면 되고, 그 첫 인자에 맞게 jump table을 참조하여 다음 인자를 고르면 됩니다.
Answer
0 207
phase4
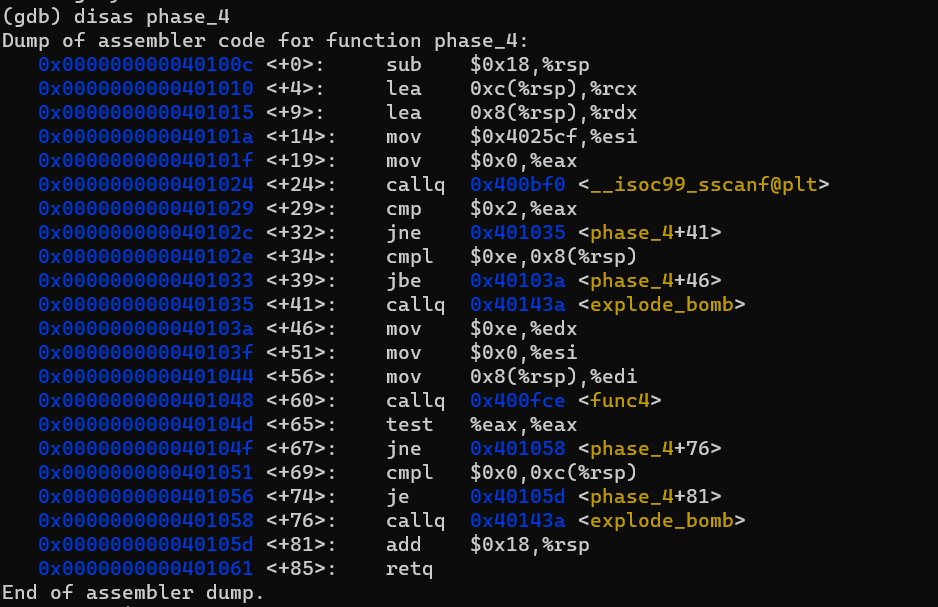
앞단계에서처럼, 입력 형식을 알아봅니다.

공백 하나를 사이에 두고 십진수 두 개를 입력해야함을 알 수 있습니다.
<+60> 전까지는 사용자의 입력을 받고, 조건에 맞게 입력이 되었는지 확인하는 내용이니 건너뛰고 func4 함수를 보겠습니다.
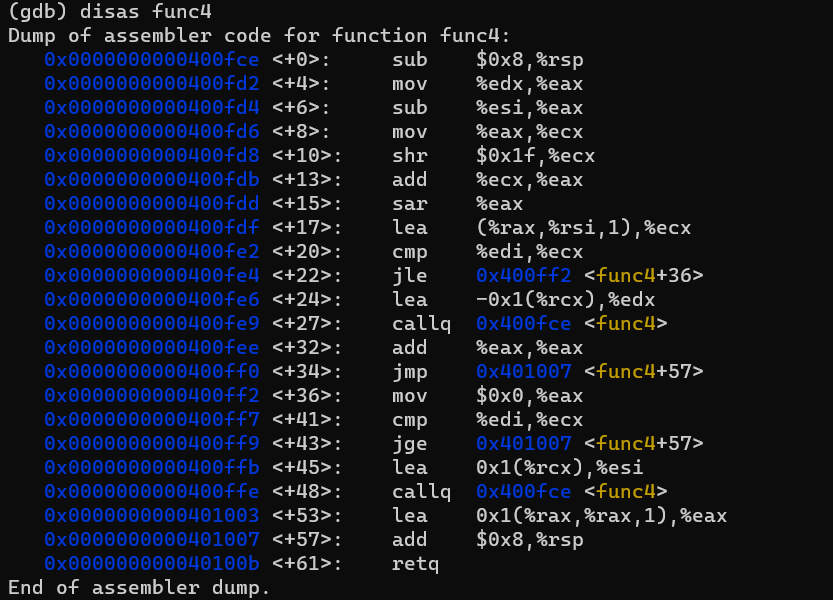
재귀적인 구조라는 것을 알 수 있습니다.
<+22>에서 조건이 충족되지 않으면 재귀적으로 함수를 호출합니다. 종료조건이 충족되면 %eax에 0을 넣어주고 반환합니다.
그러면 그 마지막 함수를 호출한 함수는 이 %eax의 값에 2를 곱해주고 (<+32> 부분) 반환합니다.
이런 식으로 계속해서 재귀적으로 호출되었던 함수들이 %eax에 2를 곱해주게 됩니다.
가장 최초에 호출되었던 func4가 값을 반환하면 다시 원래의 phase_4 함수로 돌아갑니다.
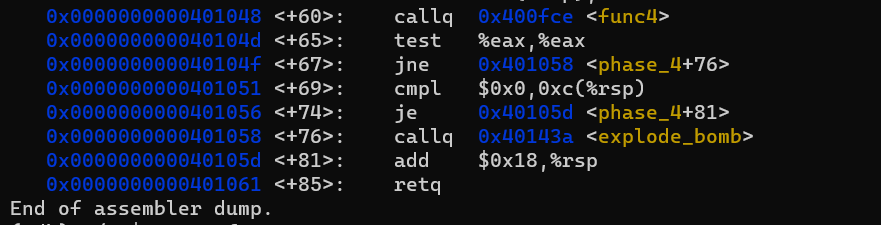
phase_4 함수의 끝부분입니다.
<+65> 부분을 보면 %eax의 값은 0이어야 함을 알 수 있습니다. \(x \times 2^k\)의 값이 0 이라면 \(x\)는 0입니다. 고로 첫번째 인자는 0을 입력해야 합니다.
<+69>와 <+74>를 보면 두 번째 인자도 0이라는 것을 알 수 있습니다.
Answer
0 0
phase5
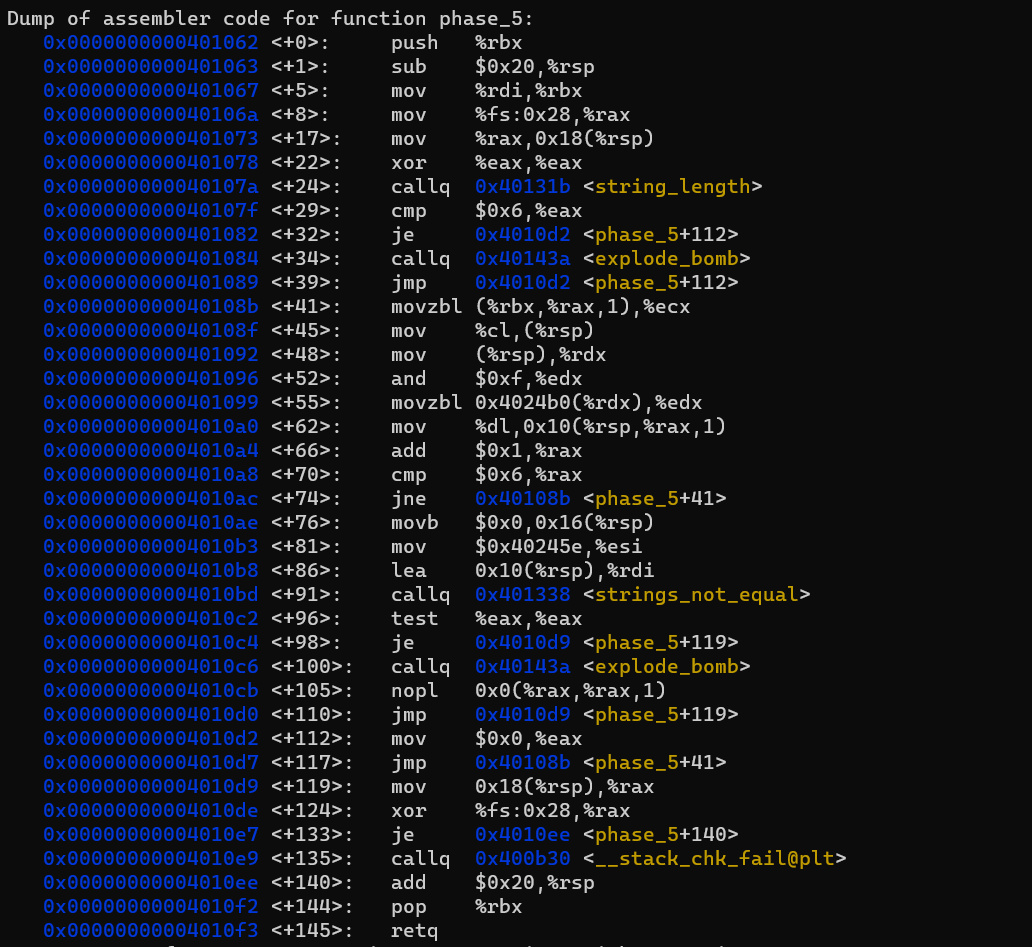
- 참고로,
<+5>, <+8>, <+22>, <+119>, <+124>, <+133>, <+135>부분은Buffer Overflow가 일어나진 않았는지 확인하는 부분입니다. 입력된 문자열이Buffer에서 넘쳐서 원래Stack의 내용물을 변경시켰는지 검사합니다. 자세한 내용은 강의Lecture 9또는 교재p.323을 참고하시면 됩니다.

먼저 비교대상이 되는 문자열을 확인해보면 flyers.
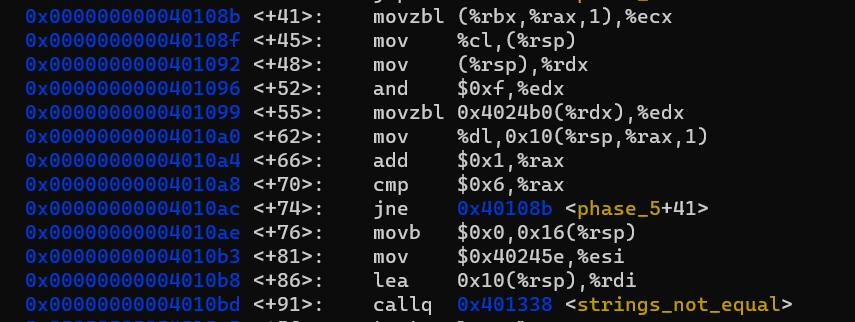
phase_5 함수에서 핵심적인 부분입니다.
string_length 함수를 보면 알 수 있듯, %rdi에는 사용자가 입력한 문자열의 시작을 가리키는 포인터가 저장되어 있습니다.
그러므로 %rbx는 문자열의 시작 주소이고 (<+5> 참고) %rax에는 0이 들어있습니다. (<+112> 참고)
반복문을 해석해보겠습니다. <+41>에서 문자열을 byte단위로 읽어오고, 반복문이 작동하며 %rax의 값이 1씩 커지니까 한 byte씩 읽어들이는 것과 마찬가지입니다.
이렇게 읽어들인 byte는 %cl(즉, %rcx의 LSB)과 %rdx에 저장됩니다.
그리고 해당 byte를 0000 1111과 & 연산을 해서 %rdx에 저장했습니다.
이제 <+55>에서 Mem[0x4024b0 + %rdx]에 접근해 알아낸 byte를 %eax에 넣습니다. 0000 1111과의 & 연산을 hash function으로 갖는 hash table이라고 볼 수 있습니다.
즉, Mem[0x4024b0 + %rdx] 값이 차례대로 f, l, y, e, r, s 여야 하는 것입니다.
아스키 코드 값을 참고하면,
f: 102
l: 108
y: 121
e: 101
r: 114
s: 115
입니다.
hash table의 내용을 확인해보겠습니다. 소문자 알파벳에 대응되는 아스키 코드 값을 가진 메모리 주소를 알고 싶으므로 일단 넉넉히 0x4024b0부터 32 byte만 확인해보았습니다.

알고보니 16개만 확인하면 됐던것 같습니다. 아무튼 이렇게 얻어낸 정보를 통해 어떻게 입력한 문자열을 hashing한 결과가 flyers가 되게 만들 것인지 알 수 있습니다.
예를 들어, f, 즉 102를 얻기 위해서는 Mem[0x4024b0 + 9]에 접근해야 합니다. 따라서 첫번째 입력할 문자는 ____ 1001(여기서 _는 0이든 1이든 상관없다는 뜻)의 아스키 코드를 가져야 합니다. 아스키 테이블을 참조하면 i, y, Y, ) 등이 있습니다. 이 중 아무거나 가져다 쓰면 됩니다. 어차피 hash function을 거치면 똑같은 메모리를 참조하게 됩니다.
답은 여러가지 경우의 수가 있습니다.
Answer
ionefg
phase6
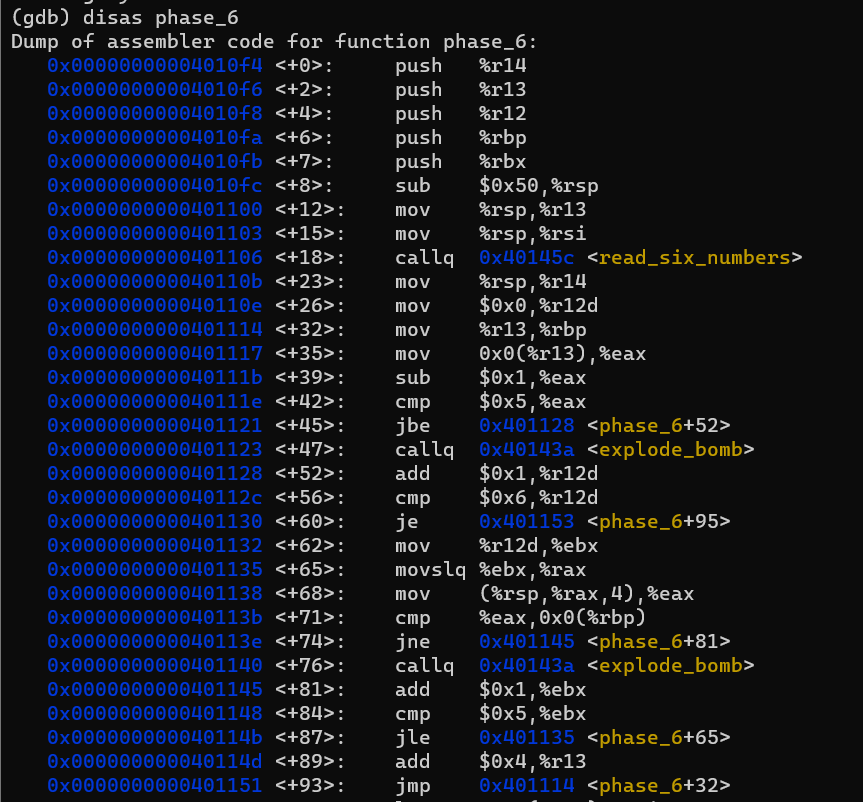
먼저 전반부를 보겠습니다.
반복문을 해석해보면, 입력받을 6개의 숫자는 모두 1 이상 6 이하여야 하고, 같은 숫자도 하나도 없어야합니다.
그러므로, 입력해야 하는 숫자는 1, 2, 3, 4, 5, 6의 순열입니다.

이어지는 부분은 입력된 수 \(d_i\)(i = 0, 1, 2, 3, 4, 5)에 대해 \(7-d_i\)를 시행합니다.
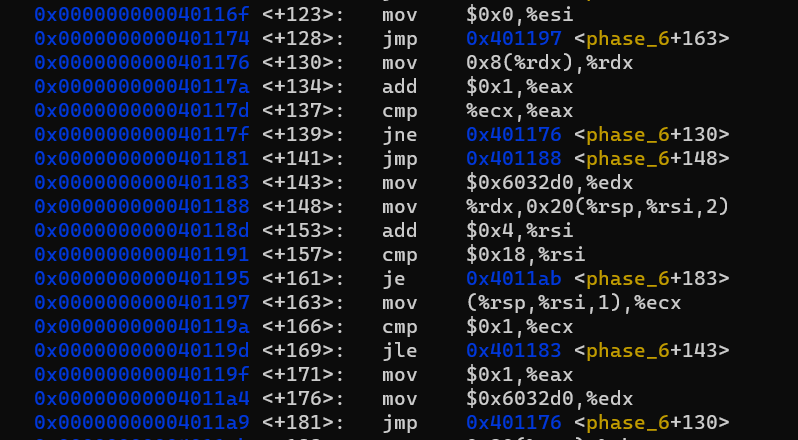
<+123>부터 <+181> 까지입니다.
중간에 보이는 0x6032d0에 뭐가 있는지부터 보겠습니다.

Linked List 입니다.
코드를 해석해보면, \(d_i\) 값에 대해 \(d_i - 1\)번만큼 Linked List를 따라 타고 간 후에 해당 Node의 주소값을 저장합니다.
예를 들어, \(d_1\)이 1이라면, Mem[%rsp + 0x20]에 0x6032d0가 저장됩니다.
\(d_i\)값에 따라 스택에 저장될 주소값을 정리하면 다음과 같습니다.
| \(d_i\) | 스택에 저장될 주소값 |
|---|---|
| 1 | 0x6032d0 |
| 2 | 0x6033e0 |
| 3 | 0x6032f0 |
| 4 | 0x603300 |
| 5 | 0x603210 |
| 6 | 0x603320 |
즉 <node1>부터 <node6>까지 순서대로 대응됩니다.
위의 숫자들이 스택의 어디에 들어가 있을지를 결정해주는건, 우리가 1, 2, 3, 4, 5, 6을 배치하는 순서입니다.
예를 들어, 1 3 2 4 5 6이 주어지면 스택은 다음과 같이 만들어집니다.
| Stack | 주소 |
|---|---|
| 0x603320 | %rsp + 0x50 |
| 0x603210 | |
| 0x603300 | |
| 0x6033e0 | |
| 0x6032f0 | |
| 0x6032d0 | %rsp + 0x20 |
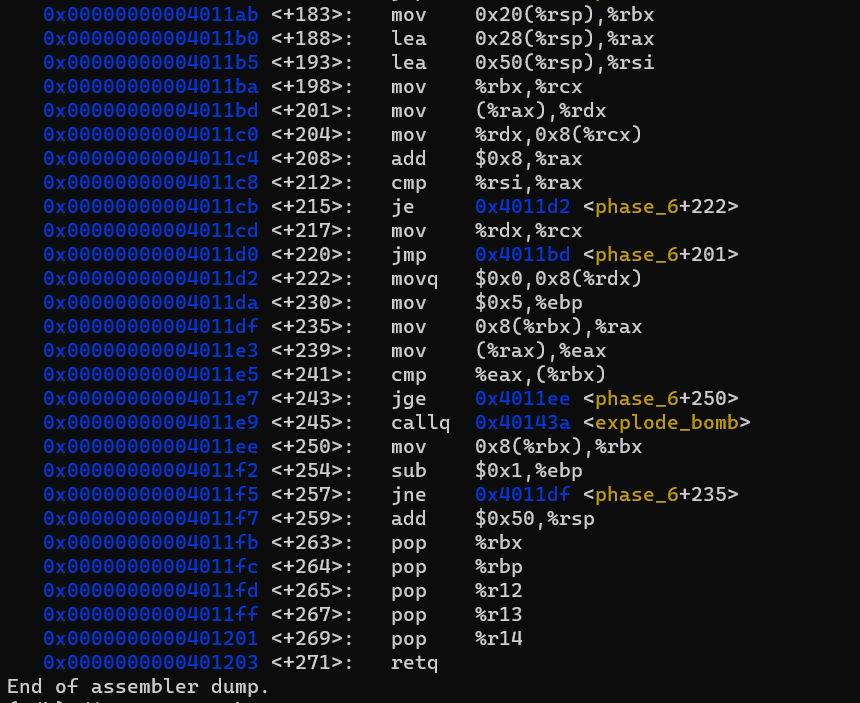
여기까지가 전체 코드입니다.
우리의 입력값으로 채워진 스택을 사용해 Linked List의 Node들을 연결하는 작업입니다.
예를 들어, 임의로 6 5 4 3 2 1을 입력(이를 위해선 1 2 3 4 5 6을 입력해야합니다. 앞에서 언급했듯 중간에 한 번 조작됩니다)하고 gdb의 break point를 이용해 Node들을 다시 보면,
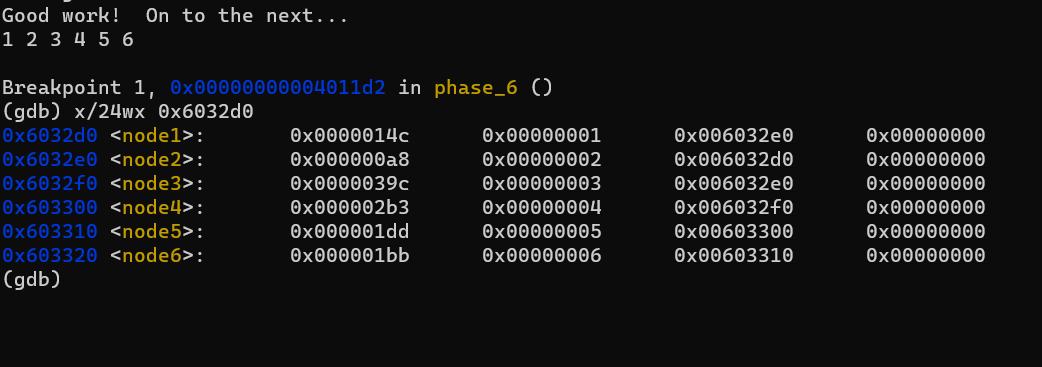
이처럼 프로그램 실행 전과는 Node들이 다르게 연결되어 있음을 알 수 있습니다.
문제는 Node들을 어떤 순서로 연결할 것인가 인데, 이는 <+241>, <+243>을 보면 알 수 있습니다. 즉, 앞선 Node의 값이 뒤따르는 Node의 값보다 커야 합니다. 내림차순으로 정렬하면 되겠습니다.
즉, <node3>이 첫번째, <node4>가 그 다음…(계속 진행)
이를 위해 우리는 <+181>까지 실행된 시점의 스택을 다음과 같은 형태로 만들고 싶습니다.
| Stack | 주소 |
|---|---|
| 0x6032e0 | %rsp + 0x50 |
| 0x6032d0 | |
| 0x603320 | |
| 0x603310 | |
| 0x603300 | |
| 0x6032f0 | %rsp + 0x20 |
종합해보면, 3 4 5 6 1 2를 입력해야 함을 알 수 있습니다.
단, 앞에서 모든 \(i\)에 대해 \(7 - d_i\)의 과정을 거쳤기 때문에 최종적으로 입력해야 하는 답은 4 3 2 1 6 5가 될 것입니다.
이렇게 입력한 후 break point를 이용해 Node들을 관찰해보면,
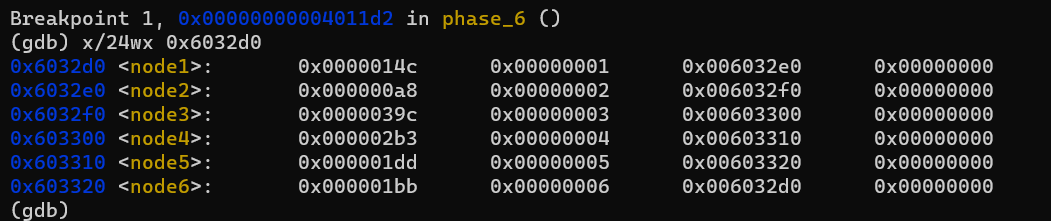
의도한대로 잘 연결되어 있습니다.
Answer
4 3 2 1 6 5
Summary
끝!
Comments