
[CSAPP] CACHE LAB 풀이
CS:APP LAB 자료 링크: http://csapp.cs.cmu.edu/3e/labs.html
혹시 잘못된 내용이 있다면 메일이나 댓글로 알려주시면 정말 감사하겠습니다
Part A
#include "cachelab.h"
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <stdbool.h>
#include <string.h>
#include <inttypes.h>
#include <getopt.h>
#include <unistd.h>
typedef struct line {
uint64_t tag;
int lru;
bool valid;
} line;
typedef line* set;
typedef set* cache;
int hits, misses, evictions;
int s,E,b,t;
FILE *trace = NULL;
bool verbose = false;
uint64_t address;
cache MyCache;
void parseArgs(int argc, char *argv[]);
void cacheSimul();
void cacheApproach(uint64_t targetTag, uint64_t setIndex);
void hit(uint64_t setIndex, int lineIdx);
void miss(uint64_t targetTag, uint64_t setIndex, int lineIdx);
void eviction(uint64_t targetTag, uint64_t setIndex);
uint64_t parseTag(uint64_t address);
uint64_t parseCacheSet(uint64_t address);
int main(int argc, char *argv[])
{
parseArgs(argc, argv);
cacheSimul();
printSummary(hits, misses, evictions); //함께 제공된 "cachelab.c" 파일에 포함된 hit, miss, eviction 횟수를 출력하는 함수.
return 0;
}
void parseArgs(int argc, char *argv[]) { //arguments parsing
int opt;
extern char* optarg;
while ((opt = getopt(argc, argv, "hvs:E:b:t:")) != -1) {
switch(opt) {
case 'h':
printf("Usage: ./csim [-hv] -s <num> -E <num> -b <num> -t <file>\n");
printf("Options:\n");
printf(" -h Print this help message.\n");
printf(" -v Optional verbose flag.\n");
printf(" -s <num> Number of set index bits.\n");
printf(" -E <num> Number of lines per set.\n");
printf(" -b <num> Number of block offset bits.\n");
printf(" -t <file> Trace file.\n");
printf("\n");
printf("Examples:\n");
printf(" linux> ./csim -s 4 -E 1 -b 4 -t traces/yi.trace\n");
printf(" linux> ./csim -v -s 8 -E 2 -b 4 -t traces/yi.trace\n");
exit(1);
case 'v':
verbose = true;
break;
case 's':
s = atoi(optarg);
break;
case 'E':
E = atoi(optarg);
break;
case 'b':
b = atoi(optarg);
break;
case 't':
trace = fopen(optarg, "r");
break;
default:
printf("Usage: ./csim [-hv] -s <num> -E <num> -b <num> -t <file>\n");
exit(1);
}
}
}
void cacheSimul() {
uint64_t numSet = ((uint64_t)1) << s; //Set의 수
MyCache = malloc(numSet * sizeof(set));
if (MyCache == NULL) exit(1);
for (uint64_t i = 0; i<numSet; i++) {
MyCache[i] = calloc(E, sizeof(line)); //MyCache[i]: 캐시의 i번째 set
if (MyCache[i] == NULL) exit(1);
}
char buffer[20];
char operation;
int size; //size는 스펙상 필요없음.
while(fgets(buffer, sizeof(buffer), trace) != NULL){
if(buffer[0] == 'I')
continue;
else{
sscanf(buffer, " %c %lx,%d", &operation, &address, &size);
uint64_t tag = parseTag(address);
uint64_t setIndex = parseCacheSet(address);
switch(operation){
case 'L':
cacheApproach(tag, setIndex);
break;
case 'M':
cacheApproach(tag, setIndex);
cacheApproach(tag, setIndex);
break;
case 'S':
cacheApproach(tag, setIndex);
break;
}
}
}
for(uint64_t i = 0; i < numSet; i++)
free(MyCache[i]);
free(MyCache);
}
void cacheApproach(uint64_t targetTag, uint64_t setIndex) {
for (int i=0; i<E; i++) {
//cold miss
if (!MyCache[setIndex][i].valid) {
miss(targetTag, setIndex, i);
return;
}
//hit
else if (MyCache[setIndex][i].tag == targetTag) {
hit(setIndex, i);
return;
}
}
//capacity miss OR conflict miss
eviction(targetTag, setIndex);
}
void hit(uint64_t setIndex, int lineIdx) {
if (verbose) printf("0x%" PRIx64 " hit\n", address);
hits++;
for (int i = 0; i<E; i++) {
MyCache[setIndex][i].lru++;
}
MyCache[setIndex][lineIdx].lru = 0; //접근했으니 lru 초기화
}
void miss(uint64_t targetTag, uint64_t setIndex, int lineIdx) {
if (verbose) printf("0x%" PRIx64 " miss\n", address);
misses++;
MyCache[setIndex][lineIdx].tag = targetTag;
MyCache[setIndex][lineIdx].lru = 0;
MyCache[setIndex][lineIdx].valid = true;
}
void eviction(uint64_t targetTag, uint64_t setIndex) {
if (verbose) printf("0x%" PRIx64 " miss eviction\n", address);
misses++;
evictions++;
int maxLru = 0;
int maxLruIdx = 0;
//LRU line index 찾기
for (int i=0; i<E; i++) {
if (MyCache[setIndex][i].lru > maxLru) {
maxLru = MyCache[setIndex][i].lru;
maxLruIdx = i;
}
MyCache[setIndex][i].lru++; //target이 아닌 line은 매번 lru를 1씩 늘려줘야하므로
}
//eviction
MyCache[setIndex][maxLruIdx].tag = targetTag;
MyCache[setIndex][maxLruIdx].lru = 0;
}
uint64_t parseTag(uint64_t address) {
uint64_t tag = (address>>(s+b));
return tag;
}
uint64_t parseCacheSet(uint64_t address) {
uint64_t mask = (((uint64_t)1) << s) - 1;
uint64_t setIndex = (address >> b) & mask;
return setIndex;
}
Part A의 코드입니다. conflict miss 또는 capacity miss가 발생했을 때 eviction rule로 사용될 LRU (Least Recently Used) Cache를 판정하는 방법에 대해서만 풀이하겠습니다. 나머지 부분은 LAB 스펙에 적혀있는대로 구현하면 돼서 간단하다고 생각합니다.
처음에는 Queue로 구현하면 되나 생각했지만, 그렇게 하면 특정 line에 2회 이상 접근하는 경우가 있을 때는 LRU를 판단하는 것이 불가능함을 알 수 있었습니다.
그래서 생각해낸 방법이, Cache에 접근할 때마다 모든 line들에 있는 lru 변수를 1씩 증가시키고, 이번 Cache 접근에서 사용된 line의 lru는 0으로 초기화해주는 것입니다. 이렇게 하면 최근에 접근한 line일수록 lru 변수는 작게 유지됩니다. 그러다 만약 eviction이 필요한 경우라면, line들 중에서 lru변수의 값이 가장 큰 line을 비우면 되는 것입니다.
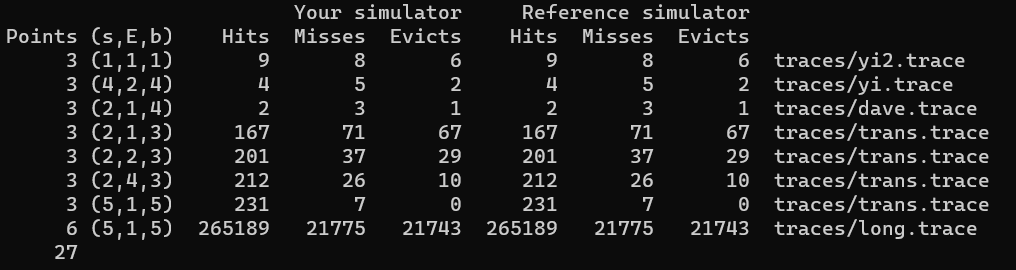
Autolab으로 채점해본 결과, 시뮬레이션이 잘 작동함을 알 수 있습니다.
Matrix Blocking
Part B를 풀기 위해서는 Matrix Blocking에 대해서 알 필요가 있습니다.
- 아래의 자료(코드와 사진)는 CS:APP 저자직강 인터넷 강의에서 제공되는 자료입니다. 이 부제목의 내용은 이를 바탕으로 필자가 이해한 바를 정리한 글입니다. 원본 자료는 http://csapp.cs.cmu.edu/public/waside/waside-blocking.pdf에서 다운받으실 수 있습니다.
Matrix Blocking 이란 locality를 활용하여 행렬계산을 최적화하기 위한 기법입니다. 코드의 가독성을 떨어뜨리게 되지만, 코드가 작동할 시스템에 맞게 잘 활용하면 큰 효울성을 얻을 수 있습니다.
예를 들어서, \(n \times n\) 행렬 \(A\), \(B\)에 대해서 \(C = A \times B\)인 행렬 \(C\)를 Matrix Blocking을 활용하여 구하는 코드는 다음과 같습니다.
(bsize는 Matrix Block의 한 변 크기, Cache block과는 다름에 주의. n은 행렬 \(A\), \(B\)의 한 행(또는 열)의 원소 수)
void bijk(array A, array B, array C, int n, int bsize) {
int i, j, k, kk, jj;
double sum;
int en = bsize * (n/bsize); /* Amount that fits evenly into blocks */
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
C[i][j] = 0.0;
for (kk = 0; kk < en; kk += bsize) {
for (jj = 0; jj < en; jj += bsize) {
for (i = 0; i < n; i++) {
for (j = jj; j < jj + bsize; j++) {
sum = C[i][j];
for (k = kk; k < kk + bsize; k++) {
sum += A[i][k]*B[k][j];
}
C[i][j] = sum;
}
}
}
}
}
저는 i를 기준으로 잡고 jj, kk의 변화에 따른 j와 k의 움직임을 생각하며 읽는 게 이해에 도움이 되었습니다.
핵심적인 아이디어는 우리가 보통 행렬곱을 할 때처럼 행과 열의 내적을 바로 구하지 않고 Cache에 올릴 수 있는 크기의 block으로 행렬들을 나누고 그 block 안에서 행렬곱 연산을 할 때처럼 내적을 구해 C[i][j]에 더해주는 것입니다. kk, jj의 for loop을 돌 때마다 그 결과가 C[i][j]에 쌓이게 되고, 결과적으로 반복문이 끝나면 행렬곱의 결과가 행렬 \(C\)에 남게 됩니다.
이해를 돕기위해 강의자료에 제공된 사진을 첨부하겠습니다.
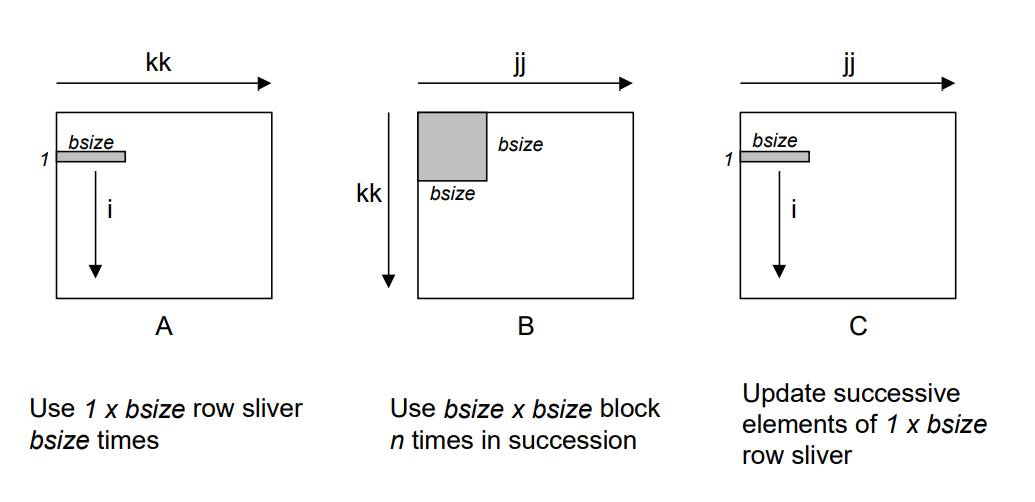
이 코드가 일반적으로 행렬곱을 구하는 것보다 빠른 이유는 행렬 \(A\), \(C\)에 접근할 때 항상 연속된 주소를 참조하여 spatial locality를 잘 활용하기 때문입니다. 행렬 \(B\)에 접근할 때도 만약 block size가 block 전체를 Cache에 올릴 수 있을만큼 충분히 작다면 Cache의 빠른 접근속도를 누릴 수 있습니다.
위 함수의 이름이 bijk인 것은 for loop의 바깥쪽에서부터 i, j, k 순서로 작성되어 있기 때문입니다. 같은 규칙으로 이름 지은 다른 행렬곱을 구하는 함수들과 performance를 비교한 그래프입니다.
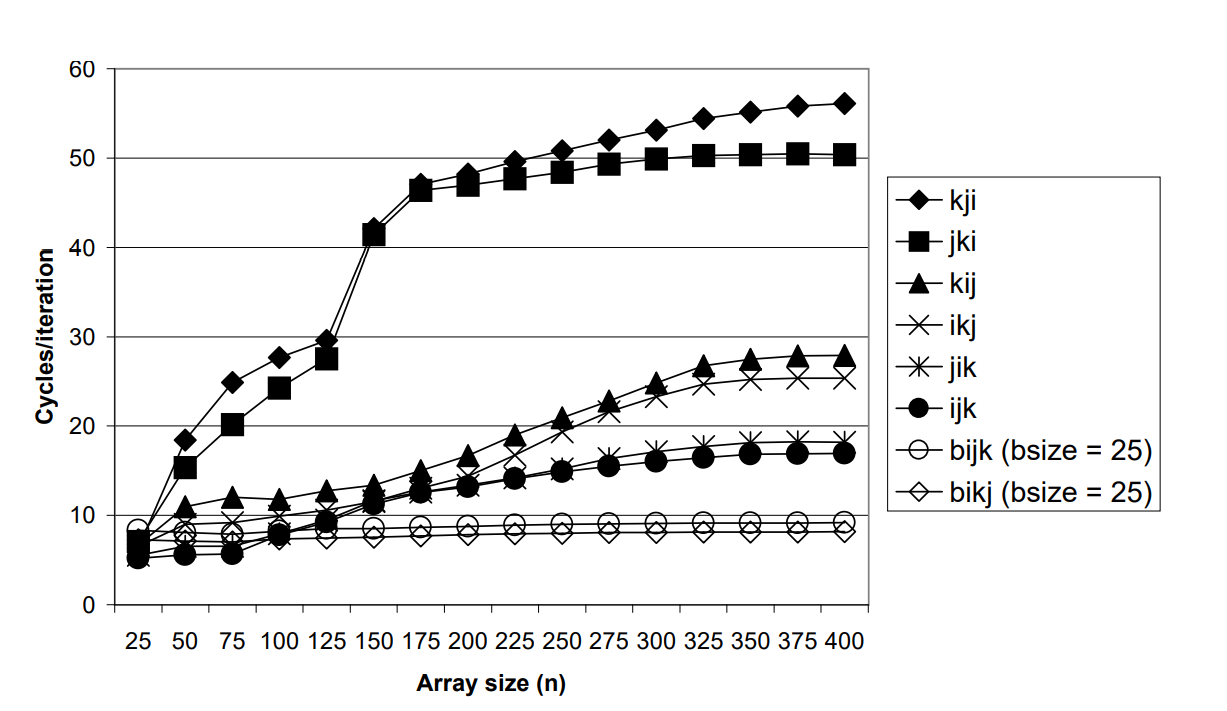
위 그래프를 보면 Cache를 잘 활용하는 것이 얼마나 중요한지 체감할 수 있습니다.
Part B
과제 스펙:
- 32 set
- 1 line / set
- 32 byte block / line
위와 같은 Cache를 가정하고 Cache Miss를 최소화하면서 \(32 \times 32 , 64 \times 64, 67 \times 61 \) 행렬을 전치하는 함수를 작성하는 것이 Part B의 내용입니다.
\(32 \times 32\) 풀이 코드입니다.
void transpose_submit(int M, int N, int A[N][M], int B[M][N]) {
int bSize = 8;
int ii, jj, i, j;
for (ii = 0; ii<N; ii+=bSize) {
for (jj = 0; jj<M; jj+=bSize) {
for (i = ii; i< ii + bSize; i++) {
for (j = jj; j< jj + bSize; j++) {
B[j][i] = A[i][j];
}
}
}
}
}
자료형은 int이므로 line 하나당 8개의 원소가 들어갈 수 있습니다. 그리고 line은 32개 있으므로, ‘16행 8열’로 Matrix Block을 설정해도 원래의 행렬인 \(A\)의 Matrix Block과 이 Block을 전치해서 옮겨야 하는 목적지인 행렬 \(B\)의 Matrix Block을 모두 Cache에 담아서 작업할 공간은 있습니다.
다만 그러려면 행렬 \(A\)와 행렬 \(B\)의 메모리 주소값이 아주 운좋게 set index를 구함에 있어서 겹치는 일이 없도록 (즉, 겹치는 일 없이 32개의 set에 모두 분배되도록) 주어져야 합니다.
과제 스펙으로 주어진 조건상 현재 Direct Mapped Cache를 가정하기 때문에 만약 set index가 하나라도 겹친다면 바로 Conflict Miss가 발생하게 됩니다.
공간이 남는 비효율성이 있더라도 Miss가 발생하는 것보단 낫다고 생각해 ‘8행 8열’을 하나의 Matrix Block으로 설정하였습니다.
이후 그냥 Block단위로 전치하고 행렬 \(B\)의 적절한 장소에 넣으면 됩니다.
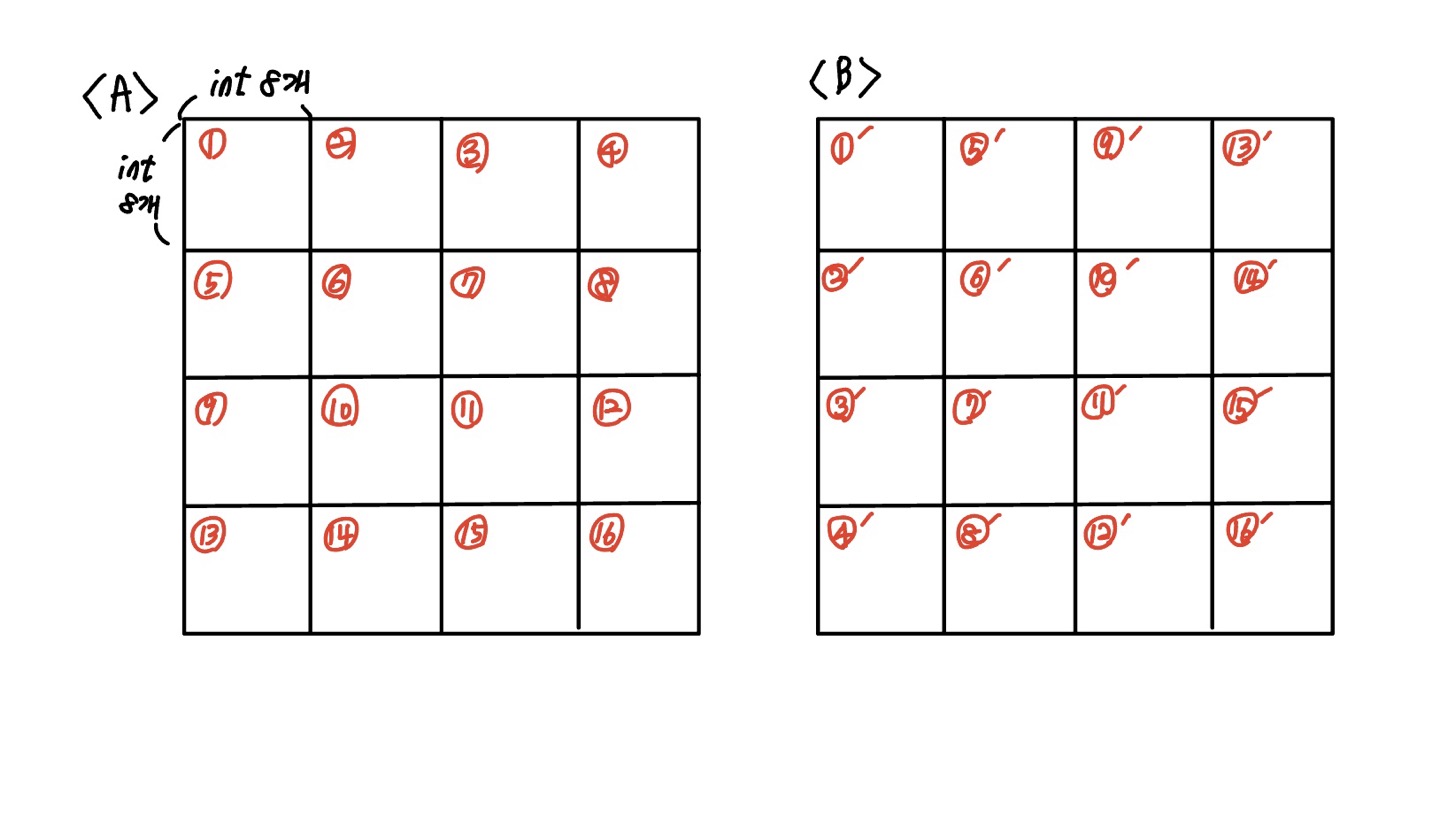
그림으로 표현하면 다음과 같습니다. 행렬 \(A\)의 1번 Block을 전치한 것을 1’번 Block 으로 표기했습니다.
급하게 다음학기에 예습해야할 내용이 생겨서 일단은 \(32 \times 32\) 케이스만 풀겠습니다ㅜㅜ 나머지 케이스들은 여유가 된다면 겨울방학에 풀어보고 업데이트하도록 하겠습니다.
Comments